A while back I worked a cloud purple-team assessment where the remediation was almost entirely Azure Policy (prevent) plus resource-change detection (detect), iterated against a resilience rubric: attack a technique, see whether it was blocked, alerted, or merely logged, write the control that would stop it, then re-attack to prove the fix. It works, but by hand it is slow, and the scoring drifts between people. I wanted to see how much of that loop I could hand to a machine, and specifically whether the blue side could learn from its own failures instead of me hand-writing every policy.
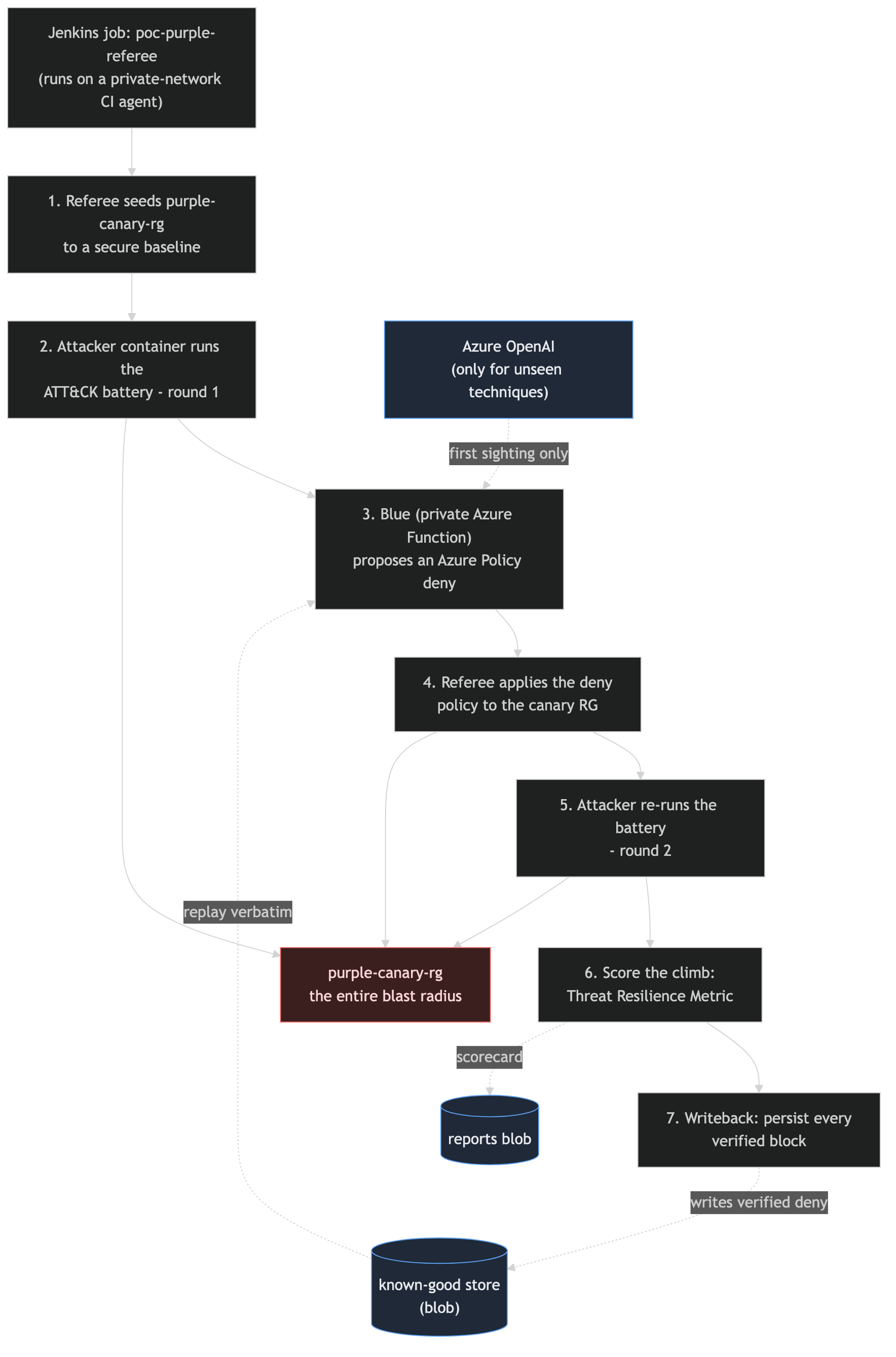
The result is a proof of concept I have been calling poc-purple. An attacker container runs an ATT&CK-mapped battery against a throwaway resource group, an AI "blue" proposes the Azure Policy that would deny each technique, a referee applies it and re-attacks to prove the block, and every policy that provably works gets banked so it is replayed verbatim next time. This post is how it fits together, the one wrong turn I took, and a few of the attacks with the exact policy the loop produced.
The loop
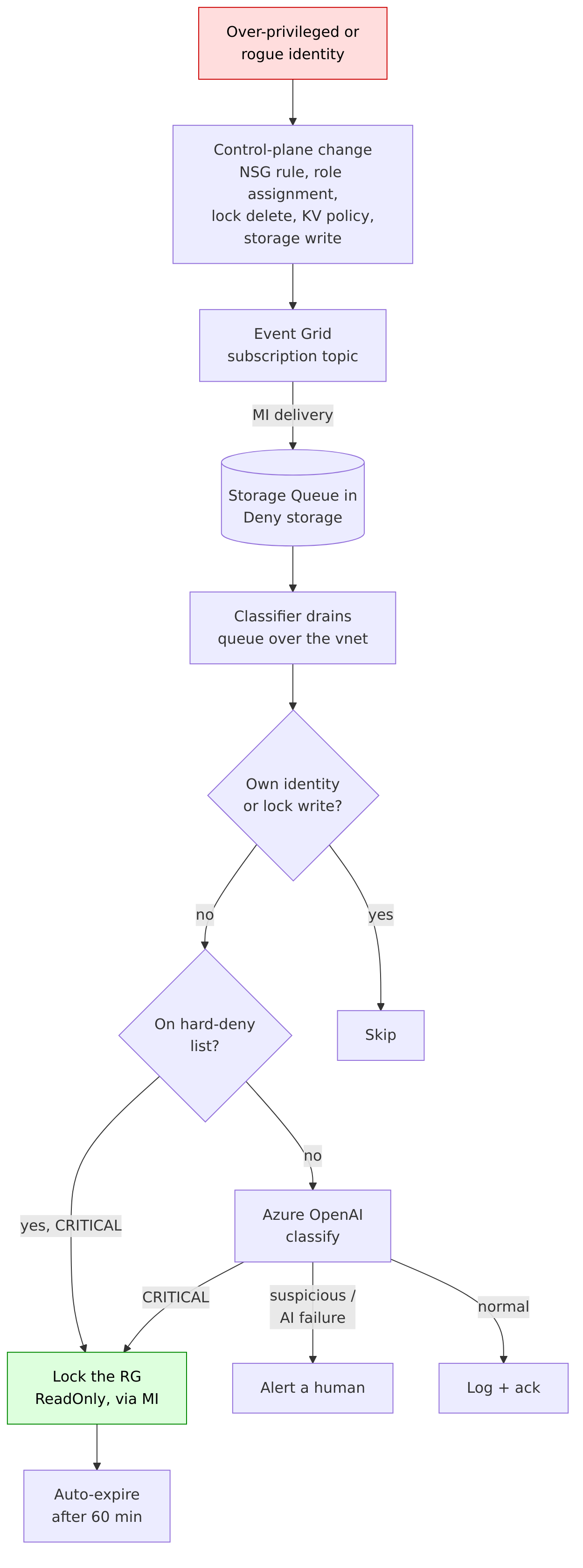
One round is seven steps. A Jenkins job (the referee) seeds a canary resource group to a known-good secure baseline. An attacker container runs the battery as a least-privileged identity scoped only to that resource group. Each technique is scored on a ladder: blocked, alerted, centrally logged, or nothing. Anything below blocked that a policy could deny is sent to blue, a private Azure Function, which returns the narrowest Azure Policy deny for that exact technique. The referee applies the policy to the canary, runs the attacker a second time, and scores the climb as a Threat Resilience Metric: of the techniques that executed and got a policy, how many are blocked now. The canary resource group is the entire blast radius. Nothing else in the subscription is touched.
The wrong turn: you cannot prompt your way to reliable Azure Policy
The first version had blue free-author the deny rule with a model on every run. It scored about four out of five, but it was a different four out of five each run. The model is not deterministic: one run it writes a working deny for a technique, the next run it over-constrains the same rule with an extra condition that does not match at evaluation time, and the attack slips through. I spent a while trying to fix this by tightening the system prompt. That was the wrong turn. Hardening the prompt fixed one technique and broke another that had blocked three runs in a row. Prompt-tuning Azure Policy generation is whack-a-mole.
The fix was to stop trusting the model on every run. When a policy provably blocks on the round-two re-attack, the referee writes it to a known-good store (a blob). Blue reads that store first and replays the verified rule verbatim, no model call. The model only runs the first time a technique is ever seen. Once it lands a working deny and the re-attack confirms it, that policy is banked forever and the run-to-run coin flip is gone. The model is now doing first-contact discovery, not re-deriving the same rule every night and getting it wrong a fifth of the time.
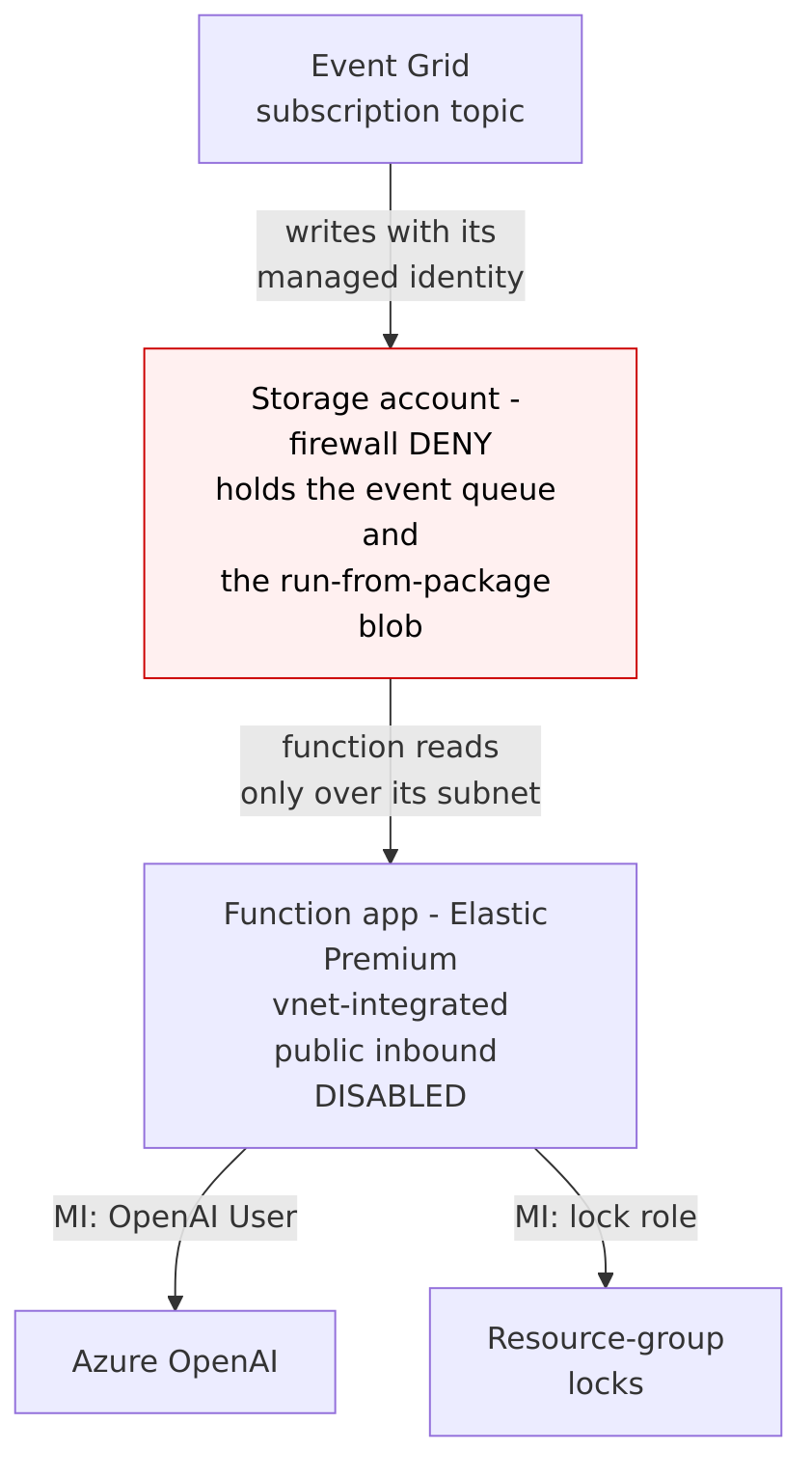
A note on the model. Blue is an Azure Function that calls a small chat model deployed in Azure AI Foundry (what used to be Azure OpenAI). It authenticates with the Function’s managed identity, so there are no API keys anywhere. The prompt is grounded, not open-ended: for the resource type under attack, blue pulls the real Azure Policy aliases (the evaluatable properties) and any deny-capable built-in definitions for that type and hands them to the model, then asks for strict JSON, the narrowest deny. That grounding is what gets the field names right, which is most of the battle with Azure Policy. The known-good store is what means the model only has to get them right once: a verified rule is replayed from the store, so the model is called only the first time a technique is ever seen, which also keeps the running cost near zero.
Sample attacks and the policy the loop produced
Each technique is a row in a table with an ATT&CK id and a callable. Here are three, with the attacker action and the exact policy rule blue produced and the referee verified.
Privilege escalation (T1098.003). The attacker grants a role to a principal it controls:
c.authz.role_assignments.create(CANARY_SCOPE, str(uuid.uuid4()), {
"role_definition_id": READER_ROLE_ID,
"principal_id": attacker_principal,
"principal_type": "ServicePrincipal"})
The resulting deny matches on the principal alone. The model learned (by getting it wrong first) that also pinning the role definition id and scope makes the rule miss at evaluation time, so the reliable rule is the minimal one:
{
"if": {
"field": "Microsoft.Authorization/roleAssignments/principalId",
"equals": "<attacker-principal-id>"
},
"then": { "effect": "deny" }
}
Route table hijack (T1599). The attacker adds a default route that sends all traffic to the internet:
c.network.route_tables.begin_create_or_update(CANARY_RG, rt.name, {
"location": rt.location,
"routes": [{"name": "attacker-route",
"address_prefix": "0.0.0.0/0",
"next_hop_type": "Internet"}]}).result()
This one is the gotcha that makes the whole banking idea worth it. The routes are an array, and Azure Policy does not evaluate a bare field match across array members. A rule that says field "...routes[*].addressPrefix" equals "0.0.0.0/0" looks right and silently fails to block. You need a count expression with a where clause. The model only lands this shape intermittently, so once it does and the re-attack confirms it, banking it is the difference between blocking this every night and blocking it one night in three:
{
"if": {
"count": {
"field": "Microsoft.Network/routeTables/routes[*]",
"where": { "allOf": [
{ "field": "Microsoft.Network/routeTables/routes[*].addressPrefix",
"equals": "0.0.0.0/0" },
{ "field": "Microsoft.Network/routeTables/routes[*].nextHopType",
"equals": "Internet" }
]}
},
"greater": 0
},
"then": { "effect": "deny" }
}
Anonymous storage (T1530). The attacker flips a storage account to allow anonymous blob access. The baseline seeds it off, so this is a real regression:
c.storage.storage_accounts.update(CANARY_RG, sa.name,
{"allow_blob_public_access": True})
The policy is the simple case, a single boolean field:
{
"if": {
"field": "Microsoft.Storage/storageAccounts/allowBlobPublicAccess",
"equals": true
},
"then": { "effect": "deny" }
}
The referee wraps whichever rule blue returns as a custom policy definition (policyType: Custom, mode: All) and assigns it to the canary resource group in Default enforcement, which is what makes it actually deny rather than audit. These are portable definitions. The storage rule above could be assigned at a subscription or management-group scope to block anonymous blob access fleet-wide. The loop is discovering real, deployable policy, not poc-only artifacts.
Growing the battery
Because the techniques are data, adding one is a row plus a canary seed for the target resource plus, for a genuinely new resource type, one line in the attacker’s least-privilege role. I added anonymous blob access and a storage TLS downgrade (both reusing the existing storage target), then a VNet DNS-redirect technique that needed a new resource type and one new action on the attacker role. Blue had never seen any of them. On the first run the model proposed a working deny for each, the re-attack confirmed it, and the writeback banked it without me hand-seeding anything. That is the whole point: the coverage climbs on its own, and every technique that gets blocked once stays blocked.
Hope that helps someone!